Apache Kafka Refreshment
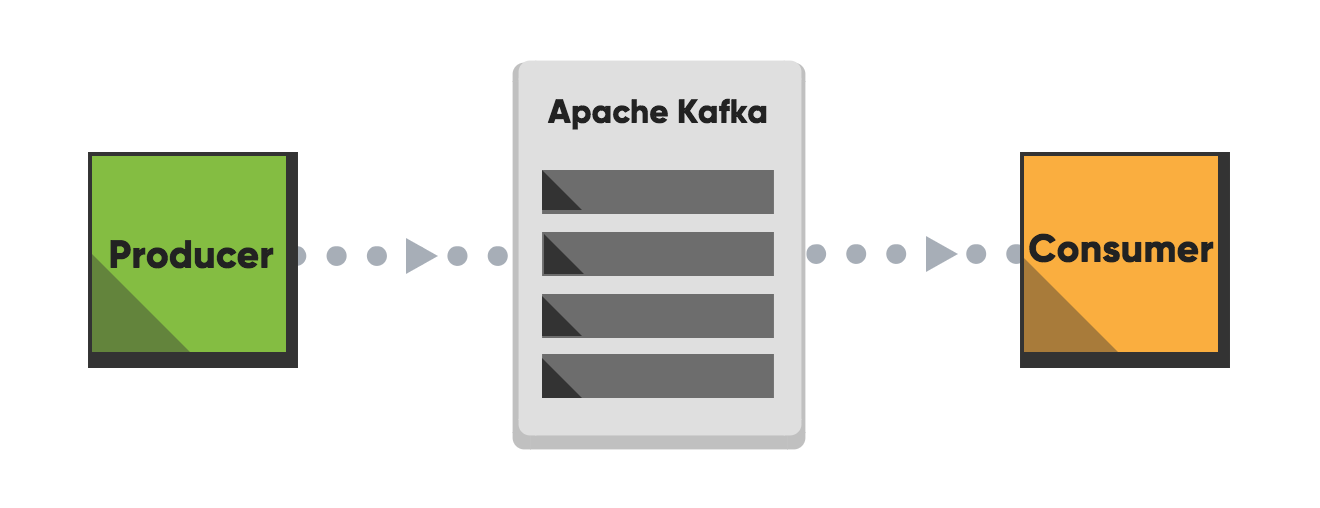
Apache Kafka is a distributed stream processing platform for big data. It’s a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system. Kafka store streams of records. Unlike most messaging systems, the log (the message queue) is persistent.
The log stream in Kafka is called a topic. Producers publish, (append), their records to a topic, and consumers subscribe to one or more topics. A Kafka topic is just a sharded write-ahead log.
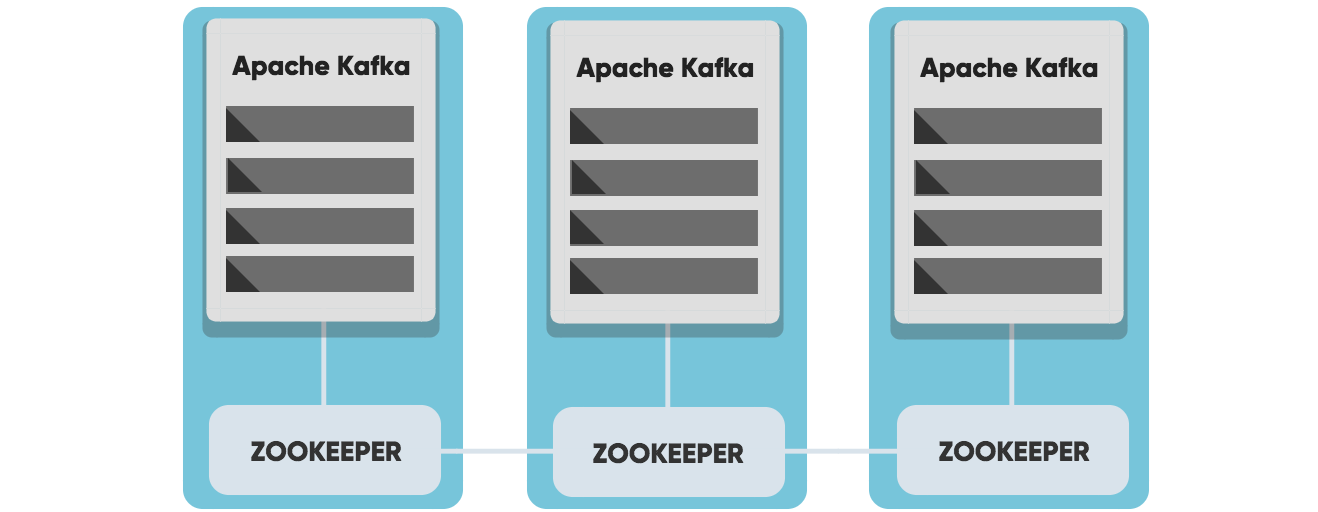
Kafka uses ZooKeeper to manage the cluster, Zookeeper keeps track of the status of Kafka cluster nodes, and it also keeps track of Kafka topics, partitions, etc.
Important Concepts
Broker
A Kafka cluster consists of one or more servers called Kafka brokers. The Kafka broker is mediating the conversation between different computer systems, like a queue in a message system. Nodes in a Kafka cluster communicate by sharing information between each other directly or indirectly using Zookeeper.
Producer
A producer writes data (records) to brokers.
Consumer
A consumer reads data (records) from the brokers.
Topics
Each Broker can have one or more topics. A Topic is a category/feed name to which messages are stored and published. If you wish to send a message you send it to a specific topic and if you want to read a message you read it from a specific topic. Messages published to the cluster will stay in the cluster until a configurable retention period has passed. Kafka retains all messages for a set amount of time or until a configurable size is reached.
Partition
Topics are split into partitions, which can be replicated between nodes. Consumers cannot consume messages from the same partition at the same time.
Record
Data sent to and from the broker is called a record, a key-value pair. The record contains the topic name and partition number. The Kafka broker keeps records inside topic partitions.
Consumer group
A consumer group includes the set of consumers that are subscribing to a specific topic. Kafka consumers are typically part of a consumer group. Each consumer in the group is assigned a set of partitions from where to consume messages. Each consumer in the group will receive messages from different subsets of the partitions in the topic. Consumer groups enable multi-machine consumption from Kafka topics.
Offset
Kafka topics are divided into a number of partitions, which contains messages in an unchangeable sequence. Each message in a partition is assigned and identified by its unique offset.
ZooKeeper
Zookeeper is a software developed by Apache that acts as a centralized service and keeps track of the status of the Kafka cluster nodes, and it also keeps track of Kafka topics, partitions, etc.
 Performance optimization for Apache Kafka - Producers
Performance optimization for Apache Kafka - Producers
The producer in Kafka is responsible for writing the data to the Kafka Brokers and can be seen as the triggers in the Apache Kafka workflow. The producer can be optimized in various ways to meet the needs for your Apache Kafka setup. By refining your producer setup, you can avoid common errors and ensure your configuration meets your expectations.
This guide is divided into three parts, and this first one, will focus on the Producers.
Ack-value
An acknowledgment (ACK) is a signal passed between communicating processes to signify acknowledgment, i.e., receipt of the message sent. The ack-value is a producer configuration parameter in Apache Kafka, and can be set to following values:
- acks=0 The producer never waits for an ack from the server. No guarantee can be made that the server has received the message, and the retries configuration will not take effect since the server will never know that the message was lost. This means that you got a low cost while sending your message, but you might pay your price in message durability.
- acks=1 The producer gets an ack after leading replica has received the data. The leader will write the record to its local log but will respond without awaiting a full acknowledgment from all followers. The message will be lost only if the leader fails immediately after acknowledging the record, but before the followers have replicated it. This means that you got a higher cost while sending your message, and not maximum, but high, durability.
- acks=all The producer gets an ack after all-in sync replicas have received the data. The leader will wait for the full set of in-sync replicas to acknowledge the record. This means that it takes a longer time to send a message, but gives strongest message durability.
How should you set the ack value for the producer in Apache Kafka?
For the highest throughput set the value to 0. For no data loss, set the ack-value to all (or -1). For high, but not maximum durability and for high but not maximum throughput - set the ack-value to 1. Ack-value 1 can be seen as an intermediate between both of the above.
Batch messages in Apache Kafka
Messages can be sent together in a specific way as groups, called a batch. The batch can then be sent when specified criteria for the batch is met; when the number of messages for the batch has reached a certain number or after a given amount of time. Sending batches of messages is recommended since it will increase the throughput.
Always keep a good balance between building up batches and the sending rate. A small batch might give you a low throughput and lots of overhead. However, a small batch is still better than not using batches at all. A too large batch might take a long time to collect, keeping consumers idling. This depends on the use case; if you have a real-time application make sure you don't have large batches.
Compression of Large messages
The producer can compress records, and the consumer can decompress them. We recommend that you compress large messages to reduce the disk footprint, and also the footprint on the wire. It’s not meant to send large files through Kafka. Put large files on shared storage instead of sending it through Kafka. Read more about compression in Apache Kafka here.
Performance optimization for Apache Kafka - Brokers
The Kafka Broker is the central part of Kafka. It receives and stores log messages until the given retention period has exceeded. By refining your broker setup, you can avoid common errors and ensure your configuration meets your expectations.
Topics and Partitions
Kafka topics are divided into a number of partitions, which contains messages in an unchangeable sequence. Each message in a partition is assigned and identified by its unique offset. A topic can have multiple partition logs.
More Partitions Lead to Higher Throughput
The number of consumers is equal to the number of partitions. One partition will only be able to handle one consumer. Multiple partitions allow for multiple consumers to read from a topic in parallel, meaning that you will have a more scalable system. With more partitions, you can handle a larger throughput since all consumers can work in parallel.
Do not set up too many partitions
Partitions are the key to Kafka scalability, but that does not mean that you should have too many partitions. We have seen a few customers with way too many partitions which in turn consumes all resources from the server. Each partition in a topic uses a lot of RAM (file descriptors). The load on the CPU will also get higher with more partitions since Kafka needs to keep track of all of the partitions. More than 50 partitions for a topic are rarely recommended good practice.
Keep a good balance between cores and consumers
Each partition in Kafka is single threaded, too many partitions will not reach its full potential if you have a low number of cores on the server. Therefore you need to try to keep a good balance between cores and consumers. You don’t want to have consumers idling, due to fewer cores than consumers.
Kafka Broker
A Kafka cluster consists of one or more servers (Kafka brokers), which are running Kafka.
How many brokers should we have?
In Kafka, replication is implemented at the partition level. Kafka automatically failover to these replicas when a server in the cluster fails so that messages remain available in the presence of failures. Each partition of a topic can be replicated on one or many nodes, depending on the number of nodes you have in your cluster. This redundant unit of a partition is called a replica. By having replicas, your data can be found on multiple places. The number of replicas you have for your topic is specified by you when you create the topic. The number of replicas can be changed in the future. The minimum number of in-sync replicas specify how many replicas that need to be available for the producer to successfully send messages to a partition.
A higher number of minimum number of in-sync replicas gives you higher persistency, but on the other hand, it might reduce availability, since the minimum number of replicas given must be available before a publish. If you have a 3 node cluster and minimum in-sync replicas is set to 3, and one node goes down, the other two are not able to receive any data.
You only care about the minimum number of in-sync replicas when it comes to the availability of your cluster and reliability guarantees. The minimum number of in-sync replicas has nothing to do with the throughput. Setting the minimum number of in-sync replicas to larger than 1 may ensure less or no data loss, but throughput varies depending on the acks configuration.
Partition load between brokers
The more brokers you have in your cluster, the higher performance you get since the load is spread between all of your nodes. A common error is that load is not distributed equally between brokers. You should always keep an eye on partition distribution and do re-assignments to new brokers if needed, to ensure no broker is overloaded while another is idling.
Do not hardcode partitions
Keys are used to determine the partition within a log to which a message is appended to. A common error is that the same key is used when sending messages, making every message ending up on the same partition. Make sure that you never hardcode the message key value.
How many partitions should we have?
How many partitions you should have depends on your need. A higher number of partitions is preferable for high throughput in Kafka, although a high number of partitions will put more load on the machines and might affect the latency of messages. Consider your desired result and don't exaggerate.
The configuration of the Apache Kafka Broker
One thing that we have changed a lot for all CloudKarafka instances is the number of file descriptors given to Apache Kafka. All CloudKarafka brokers have a very large number of file descriptors.
The topic is created by default
When sending a message to a non-existing topic, the topic is created by default sinceauto.create.topics.enable is set to true by default in Apache Kafka.
This config can be changed so that topics are not created if they do not exist. This configuration can be helpful in the matter of minimizing mistakes caused by misspelling or miscommunication between developers. Send us an email if you would like to change the default value of auto.create.topics.enablein your CloudKarafka cluster.
Change default Minimum In-sync Replicas
Default minimum In-sync Replicas is set to 1 by default in CloudKarafka, meaning that the minimum number of in-sync replicas that must be available for the producer to successfully send messages to a partition must be 1. This setting can be changed to a higher number if higher persistency is required. Send us an email if you would like to change the default minimum in-sync replicas in your cluster.
Default Retention Period
A message sent to a Kafka cluster is appended to the end of one of the logs. The message remains in the topic for a configurable period of time or until a configurable size is reached or until the specified retention for the topic exceeds. The message stays in the log, even if the message has been consumed.
Message Order in Kafka
One partition will guarantee an unchangeable sequence of your logstream. Two or more partitions will break the order since the order is not guaranteed between partitions.
Messages sent within Apache Kafka can be strictly ordered, even though your setup contains more than one partition. You will achieve a strict order of messages by setting up a consistent message key that sorts messages in the order specified, for example, user-ID. This will guarantee that all messages from a specific user always ends up in the same partition.
Please note that if the purpose of using Apache Kafka requires that all messages must be ordered within one topic, then you have to use only one partition.
Number of Zookeepers
Zookeeper requires a majority of servers to be functioning. If you, for example, have 5 servers in your cluster, you would need 3 servers to be up and running for Zookeeper to be working.
I.e., you can afford to lose one Zookeeper in a 3 node cluster, and you can afford to lose 2 Zookeeper in a 5 node cluster.
What type of server do I need for Apache Kafka?
What you need when setting up a Kafka cluster is lots of memory. The data sent to the broker is always written to disk, but it also stays in the memory for as long as there is space to keep it in there. More memory will give you a higher throughput since Kafka Consumers, first of all, try to read memory data.
Kafka does not require high CPU, as long as you are not running too many partitions.
Performance optimization for Apache Kafka -Consumers
Kafka Consumers reads data from the brokers and can be seen as the executor in the Apache Kafka three-stage rocket. By refining your consumer setup, you can avoid common errors and ensure your configuration meets your expectations. This guide is divided into three parts, and this is part three. The previous and following blog post focuses on the Producers and Brokersin the Apache Kafka symbiosis.
Apache Kafka Consumer
Consumers can read log messages from the broker, starting from a specific offset. Consumers are allowed to read from any offset point they choose. This allows consumers to join the cluster at any point in time.
A consumer can join a group, called a consumer group. A consumer group includes the set of consumer processes that are subscribing to a specific topic. Consumers in the group then divide the topic partitions fairly amongst themselves by establishing that each partition is only consumed by a single consumer from the group, I.e., each consumer in the group is assigned a set of partitions to consume from. Kafka guarantees that a message is only read by a single consumer in the group.
Make sure all consumers in a consumer group have a good connection
Partitions are redistributed between consumers every time a consumer connects or drop out of the consumer group. This means that consumers in the group are not able to consume messages during this time. If one consumer in a group has a bad connection, the whole group is affected and will be unavailable during every reconnect. A distribution of partitions takes around 2-3 seconds or longer. To make sure your setup is running smoothly, we strongly recommend you to secure the connection for your consumers.
Number of consumers
Ideally, the number of partitions should be equal to the number of consumers.
- Number of consumer > number of partitions If the number of consumers is greater, some consumers will be idling, i.e., you will be wasting client resources.
- Number of partitions > number of consumers Some consumers will read from multiple partitions if the number of partitions is greater than the number of consumers.
As mentioned before, the availability will be affected if one consumer has a bad connection. The more consumers you have, the larger risk there is, that one might drop and halt all other consumers.
No comments:
Post a Comment