Given the root of a binary tree and an integer targetSum, return all root-to-leaf paths where each path's sum equals targetSum.
A leaf is a node with no children.
Example 1:
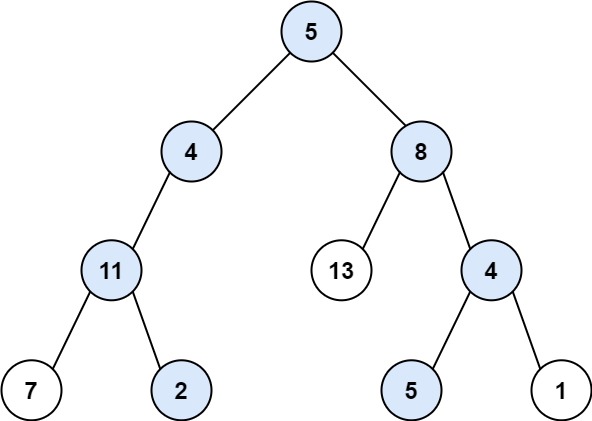
Input: root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 Output: [[5,4,11,2],[5,8,4,5]]
Example 2:
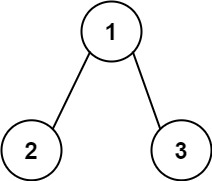
Input: root = [1,2,3], targetSum = 5 Output: []
Example 3:
Input: root = [1,2], targetSum = 0 Output: []
Solution
Approach: Depth First Traversal | Recursion
Intuition
The intuition for this approach is pretty straightforward. The problem statement asks us to find all root to leaf paths in a given binary tree. If you simply consider the depth first traversal on a tree, all it does is traverse once branch after another. All we need to do here is to simply execute the depth first traversal and maintain two things along the way:
- A running sum of all the nodes traversed till that point in recursion and
- A list of all those nodes
If ever the sum becomes equal to the required sum, and the node where this happens is a leaf node, we can simply add the list of nodes to our final solution. We keep on doing this for every branch of the tree and we will get all the root to leaf paths in this manner that add up to a certain value. Basically, these paths are branches and hence the depth first traversal makes the most sense here. We can also use the breadth first approach for solving this problem. However, that would be super heavy on memory and is not a recommended approach for this very problem. We will look into more details towards the end.
Algorithm
We'll define a function called
recurseTreewhich will take the following parameters
nodewhich represents the current node we are on during recursionremainingSumwhich represents the remaining sum that we need to find going down the tree. We can also pass the current sum in our recursive calls. However, then we'd also need to pass the required sum as an additional variable since we'd have to compare the current sum against that value. By passing in remaining sum, we can avoid having to pass additional variable and just see if the remaining sum is 0 (or equal to the value of the current node).- Finally, we'll have to pass a list of nodes here which will simply contain the list of all the nodes we have seen till now on the current branch. Let's call this
pathNodes.- The following examples assume the sum to be found is 22.
At every step along the way, we will simply check if the remaining sum is equal to the value of the current node. If that is the case and the current node is a leaf node, we will add the current
pathNodesto the final list of paths that we have to return as a result.The problem statement here specifically mentions
root to leafpaths. A slight modification is to find allroot to node paths. The solutions are almost similar except that we'd get rid of the leaf check.
- An important thing to consider for this modification is that the problem statement doesn't mention anything about the values of the nodes. That means, we can't assume them to be positive. Had the values been positive, we could stop at the node where the sum became equal to the node's value.
- However, if the values of the nodes can be negative, then we have to traverse all the branches, all the way up to the roots. Let's look at a modified tree for reference.
We process one node at a time and every time the value of the remaining sum becomes equal to the value of the current node, we add the
pathNodesto our final list. Let's go ahead and look at the implementation for this algorithm.



/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private void recurseTree(TreeNode node, int remainingSum, List<Integer> pathNodes, List<List<Integer>> pathsList) {
if (node == null) {
return;
}
// Add the current node to the path's list
pathNodes.add(node.val);
// Check if the current node is a leaf and also, if it
// equals our remaining sum. If it does, we add the path to
// our list of paths
if (remainingSum == node.val && node.left == null && node.right == null) {
pathsList.add(new ArrayList<>(pathNodes));
} else {
// Else, we will recurse on the left and the right children
this.recurseTree(node.left, remainingSum - node.val, pathNodes, pathsList);
this.recurseTree(node.right, remainingSum - node.val, pathNodes, pathsList);
}
// We need to pop the node once we are done processing ALL of it's
// subtrees.
pathNodes.remove(pathNodes.size() - 1);
}
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> pathsList = new ArrayList<List<Integer>>();
List<Integer> pathNodes = new ArrayList<Integer>();
this.recurseTree(root, sum, pathNodes, pathsList);
return pathsList;
}
}Complexity Analysis
Time Complexity: where are the number of nodes in a tree. In the worst case, we could have a complete binary tree and if that is the case, then there would be leafs. For every leaf, we perform a potential operation of copying over the
pathNodesnodes to a new list to be added to the finalpathsList. Hence, the complexity in the worst case could be .Space Complexity: . The space complexity, like many other problems is debatable here. I personally choose not to consider the space occupied by the
outputin the space complexity. So, all thenewlists that we create for the paths are actually a part of the output and hence, don't count towards the final space complexity. The only additional space that we use is thepathNodeslist to keep track of nodes along a branch.We could include the space occupied by the new lists (and hence the output) in the space complexity and in that case the space would be . There's a great answer on Stack Overflow about whether to consider input and output space in the space complexity or not. I prefer not to include them.